代码堆得越多系统崩得越快:AI编程的持续演进困境与破局
三年前我第一次用AI辅助编程,那时的兴奋感至今记忆犹新。单函数生成,准确率惊人;短脚本编写,效率翻倍提升。我天真地以为,AI编程的终局已近在眼前。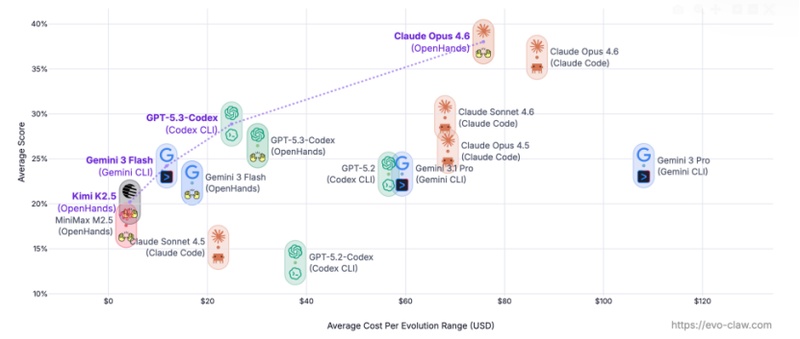
转折:从单函数到系统维护的距离
然而当我尝试用AI维护一个持续迭代的项目时,现实给了我沉重一击。代码确实在增长,功能确实在增加,但系统的脆弱性也在以指数级方式累积。每一次看似成功的功能迭代,都在为下一次崩溃埋下伏笔。
这并非我一个人的感受。腾讯首席AI科学家姚顺雨在博客《TheSecondHalf》中敏锐指出:真实编程任务是连续依赖的,而非独立并行的。这个看似简单的洞察,揭示了当下AI编程评测与真实体验之间那道难以弥合的鸿沟。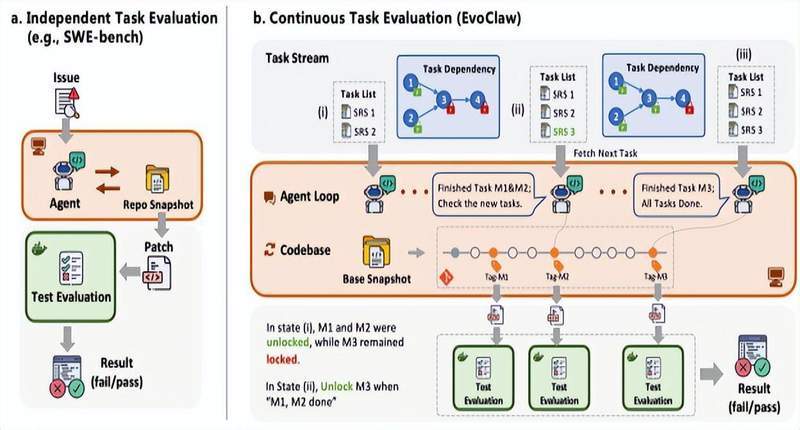
根源:评测范式的根本错位
为什么独立测评高分模型在长周期场景中集体折戟?答案在于评测范式本身。
主流编程benchmark多数聚焦独立任务:给定issue或PR,在静态代码快照上完成修复,验证通过即测评完成。这种范式简化了问题,却也剥离了软件开发最本质的特征——演进性。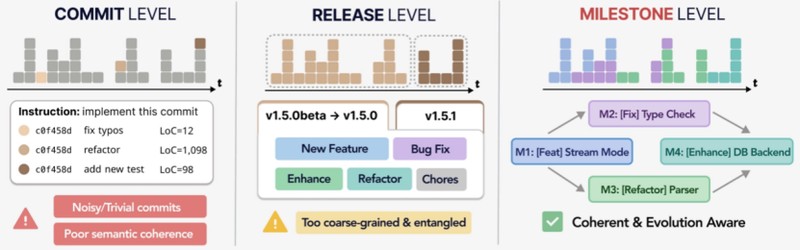
真实环境是复杂且动态的。随着时间推移,即便是数月前的微小bug,经过版本迭代也可能像滚雪球般越滚越大,最终导致系统崩溃。静态评测环境恰恰是一种过于理想的状态。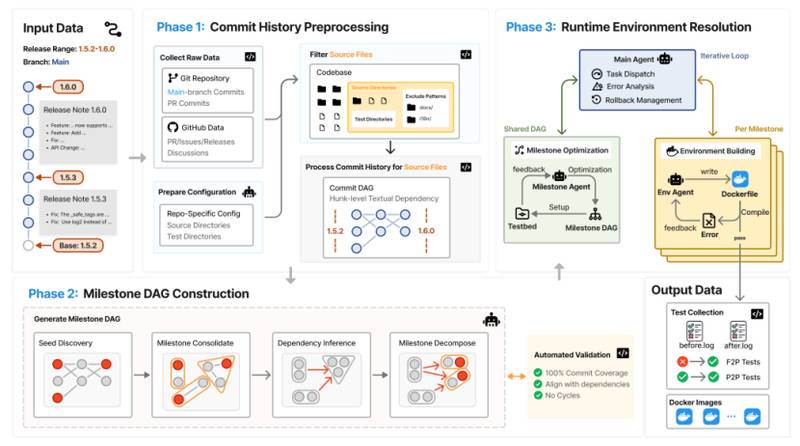
突破:EvoClaw基准的革新设计
南加州大学、斯坦福大学、普林斯顿大学等组成的联合团队发布了全新评估基准EvoClaw,首次将时间维度引入AI编程能力评估体系。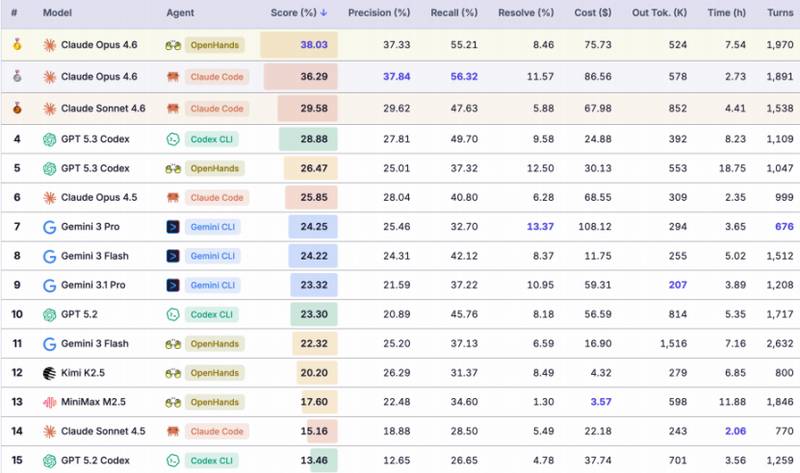
核心创新在于里程碑(Milestone)概念:对软件演进历史进行重构,提取兼具语义完整性和演进依赖关系保留能力的功能单元。AI需在同一代码库上按序完成多个功能单元,每一步产出既保留下来又成为下一步的起点。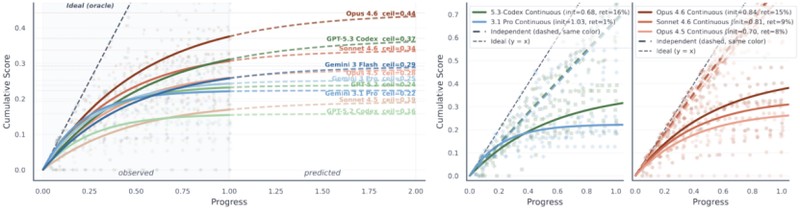
为支持从开源代码库中提取高质量演进历史,研究团队基于顶级AI能力提出了DeepCommit自动化流水线,将嘈杂的Git开发记录重构为可验证、功能内聚的里程碑任务依赖图。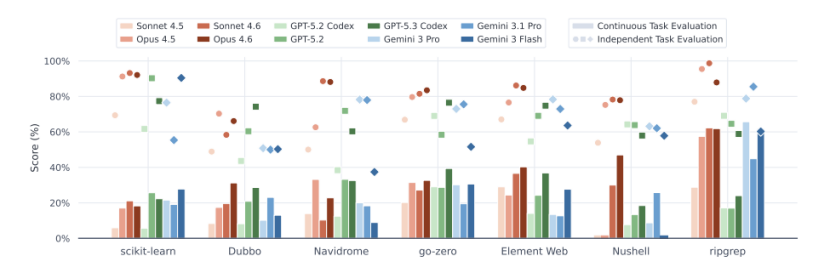
实验:断崖式下跌背后的真相
EvoClaw覆盖Python、Java、Go、Rust、TypeScript五种主流语言,项目横跨最长750天真实开发周期。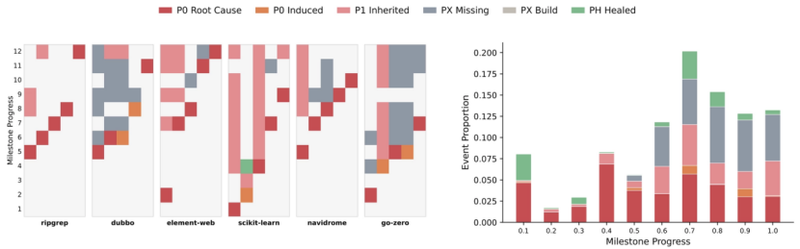
实验结果令人震惊:独立评测得分普遍在80%至90%的顶尖模型,在EvoClaw基准测试后集体断崖式下降。综合得分最高的ClaudeOpus4.6仅获得38.03分,GPT5.3Codex以28.88分位居第二。完整解决率方面,得分最高的Gemini3Pro也只有13.37%。
更关键的是,无论开发窗口多长,所有模型表现最终都会撞上天花板。任务执行顺序越靠后、所处DAG层级越深,分数和解决率就越低。饱和函数外推结果表明,即便是最优的Opus4.6,累计分数也会被卡死在45%左右的渐近线上。
洞察:错误链与技术债破产
当将整体分数分解为召回率与精确率时,一个意味深长的现象浮现:召回率几乎呈线性增长。这意味着,即便代码库变得越来越混乱、越来越脆弱,Agent依然擅长实现当前给定的新目标功能。
真正的瓶颈在于精确率。Agent难以维护现有系统,回归错误积累的速度远超修复速度。错误链分析框架揭示:新问题的产生速度并不会加快,模型甚至会实质性地被动修复部分历史错误,但前置错误的累积速度远超修复速度,最终陷入"技术债破产"。
启示:AIHarness调试的新方向
EvoClaw为AIHarnessEngineering提供了通用评估playground。当Agent表现出异常积极的迭代行为,或不断编辑、不断验证却无果时,很可能是遇到了困难。此时可在对应位置构造护栏,尽早发现问题、及时人工介入。
这一研究证明,我们正走在正确的道路上。AI的长期编程能力尚未遇到瓶颈,能够随时间稳定提升。有潜力在某一天,由榜单分数的量变,转化为改变世界的质变。
